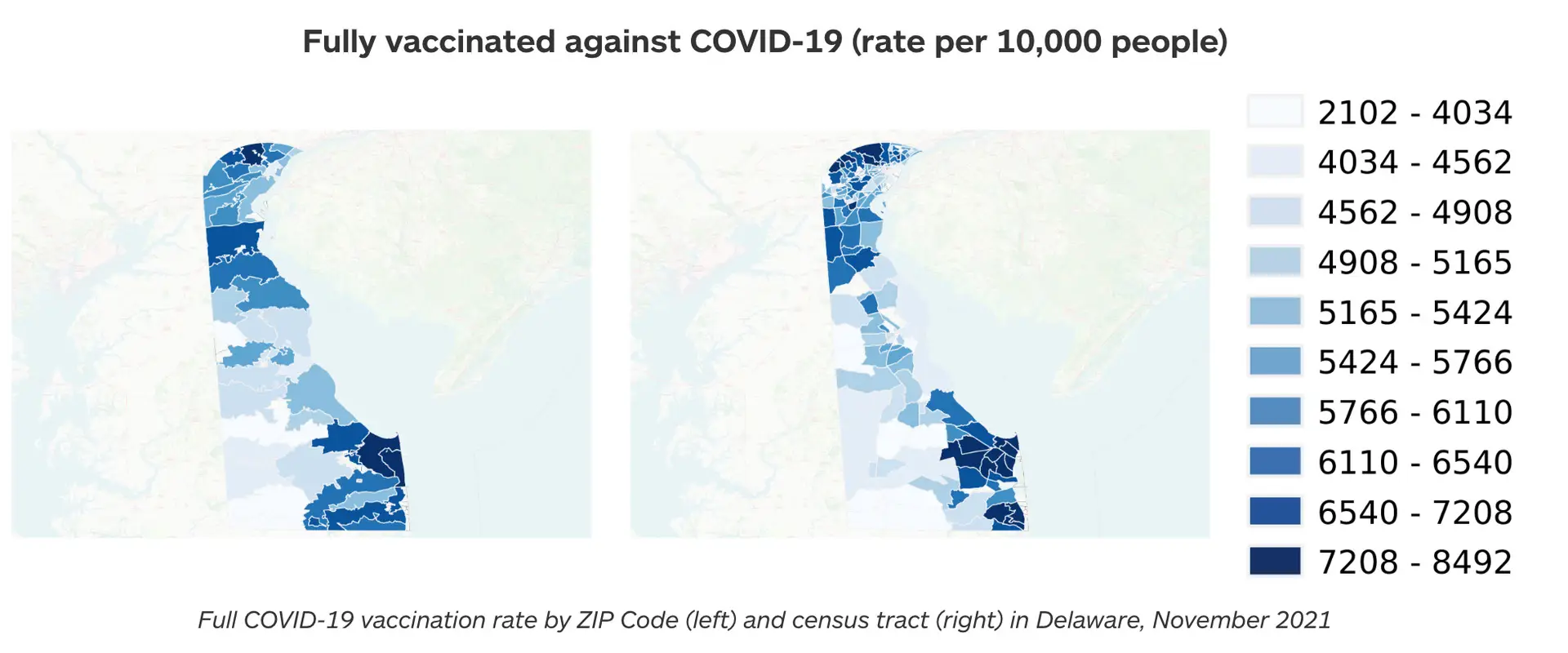
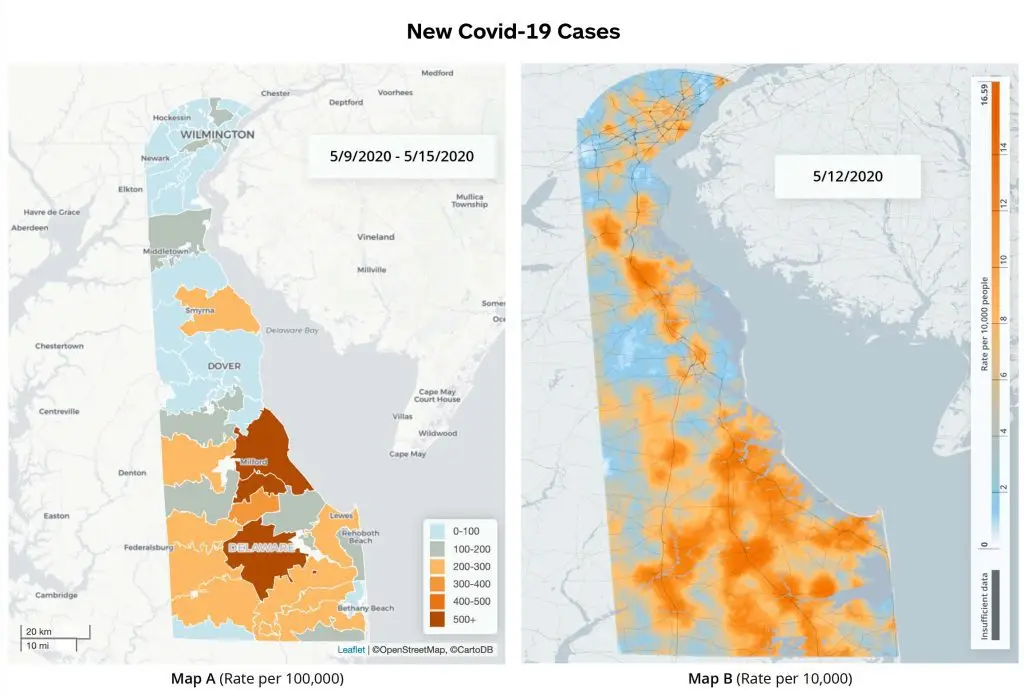
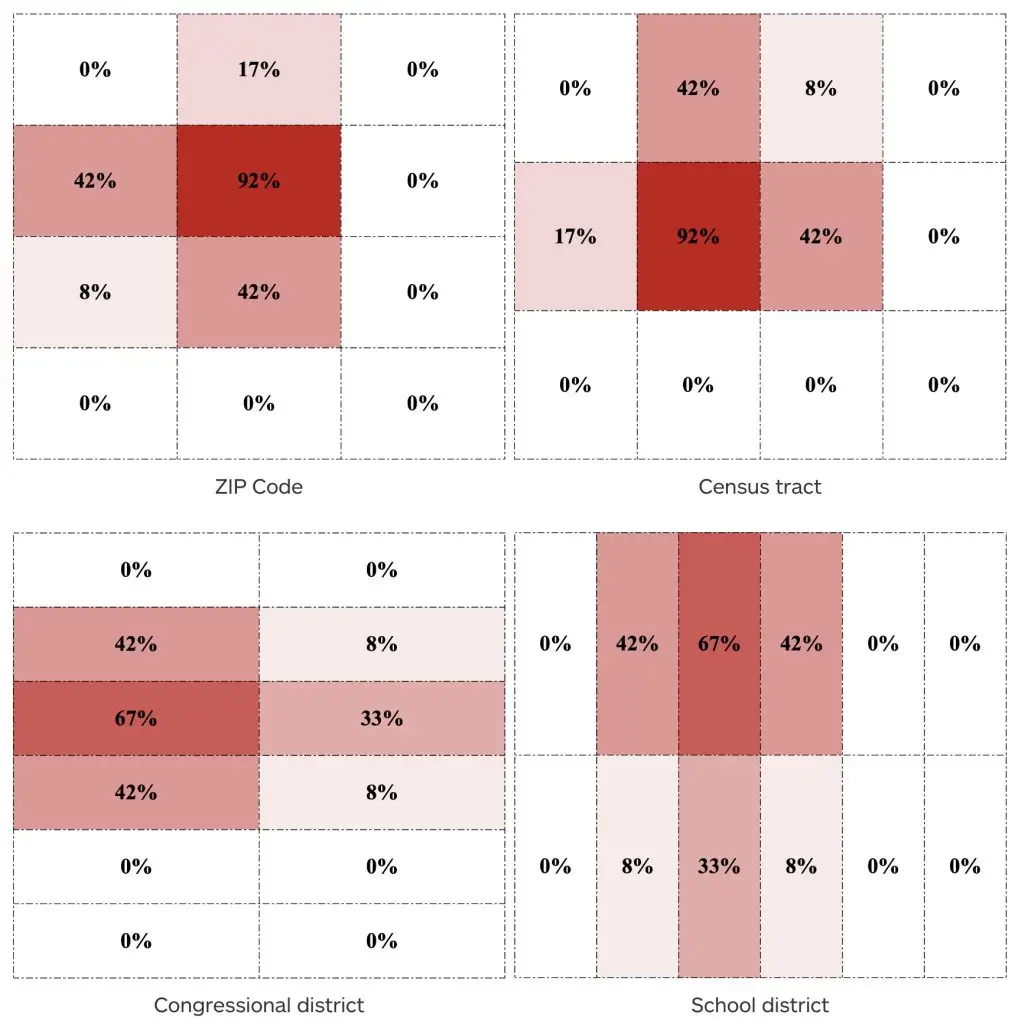
Below we outline the key steps of our process:
- Our heat map is composed of a large set of points, each assigned x, y, and z values where x and y are the point’s longitudinal and latitudinal coordinates and z represents the rate under investigation (e.g. rate of positive COVID-19 cases) calculated for that point. z will correspond to a particular color hue on a color gradient in the final heat map.
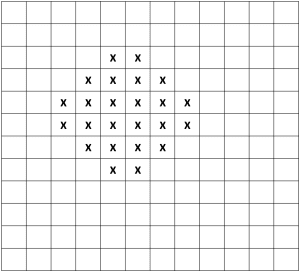
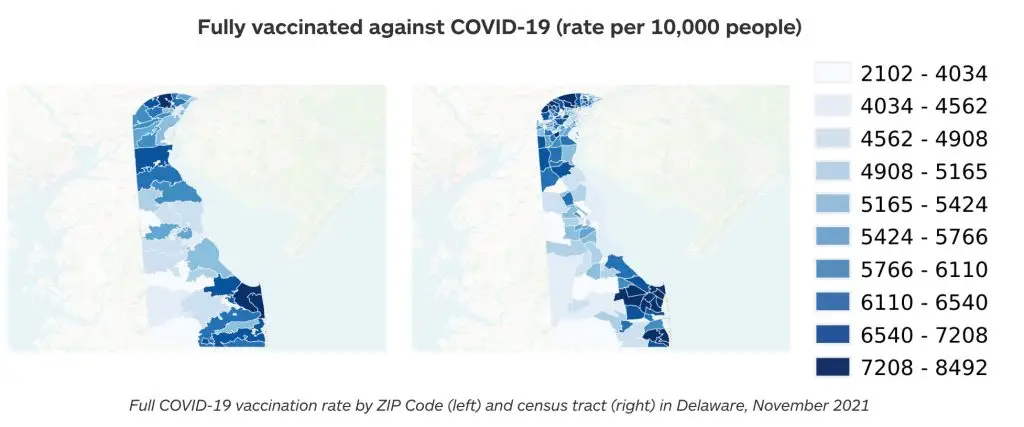
The first step is the generation of a lattice of these points, equally spaced and covering the map extent. The precise spacing is discretionary, but involves a trade-off: A dense lattice may yield greater granularity in high-population regions, but will elevate computer processing demand; a less dense lattice requires less processing power, but in the extreme might pixelate to a coarseness resembling a choropleth. In the case of the above Delaware imagery, the initial spacing between points is 0.004 degrees. - At each lattice point, a circle is initialized with a radius equal to the point spacing, which ensures that the circumference of a given lattice point’s circle touches the four closest points to its north, south, east, and west, and that the entire map surface is covered by at least once circle. [17]
Sample map with entire surface covered by at least one circle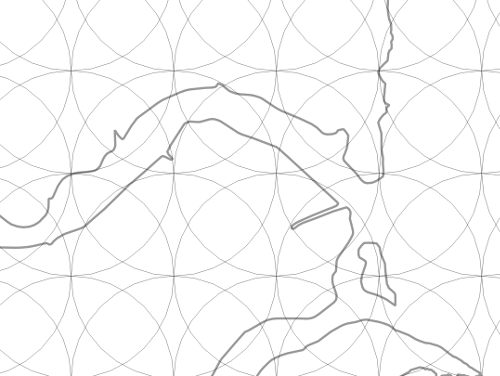
- The lattice is populated with event locations (e.g. the address of an individual with a positive COVID-19 case), which are each “snapped” from their true location to the nearest lattice point.”Snapping” serves only as a component of our HIPAA-compliant anonymization process. It is not required for calculating rates or generating heat maps and is a step that could be outright skipped in mapping contexts where privacy is of no concern.
- An anonymity test is performed based on event rates within circles. For each circle’s associated lattice point a rate is assigned as determined by:
- the number of events within the point’s associated circle (the rate’s numerator), and
- a total population (the rate’s denominator), an estimate based on the circle’s area and census data.
In general, a population estimate of ≥ 500 people and an event count of either 0 or ≥ 5 is sufficient for a circle to be considered anonymous as long as the resulting rate is less than 90 percent. [18] If a circle is not sufficiently anonymous, its size is increased to cover the next closest lattice points and the rate re-calculated. [19] At this point, either:
- the rate for the lattice point satisfies the test for sufficient anonymity, or,
- a nil value is assigned for the point’s rate after n iterations of circle expansion, with n determined experimentally. [20]
An important consequence of this process is that the events snapped to any given lattice point may count towards the rate calculation in more than one circle (and therefore be represented in the calculated rates of more than one lattice point). This means that every pixel in the final heat map represents information gathered from the surrounding area.
(Note also that, for map extents with varying population densities, the circle expansion process also executes the smoothing technique described above—circle expansion increases rate denominators, thereby lending rural rates a stability closer to those of denser regions, which in turn will minimize misleading or distracting hue fluctuations in heat map animations.
- At this stage, the process has yielded a collection of circles, each with a lattice point that has been assigned nil or a number between 0 and 1 representing a rate.
- The above process is repeated for each time period that data is available. (The static map derived from each time period in later steps will comprise a frame in the final heat map animation.)
- To assign colors to rates (i.e., the z value for each point), the full set of calculated rates across all time periods is binned into deciles and a color scale chosen to represent the entire range. The set is modified—and the standard definition of decile is deviated from—in a few ways:
- Zero rates are counted only once in a set to maximize the color range. (Otherwise, zeros, if common across the map, would consume most of the color gradient.)
- The lowest and highest 2 percent of values are excluded from the set in order to reduce the impact of outliers on the color gradient.
- The floor of the lowest bin is defined as zero regardless of the lowest value in the set.
An off-gradient color (e.g. gray) is assigned to rates with a nil value (meaning, again, the lattice point and associated circle did not reach sufficient anonymity).
- Zero rates are counted only once in a set to maximize the color range. (Otherwise, zeros, if common across the map, would consume most of the color gradient.)
- Because the lattice points themselves are not sufficiently numerous and dense to constitute a high-resolution heat map, a smoothing technique called inverse distance weighted (IDW) interpolation is applied for each time period to generate additional points (i.e. pixels) between all lattice points, each with their own z value (and associated color) interpolated according to neighbors’ values.
In this step, upon IDW interpolation, point data has effectively been converted to a true, static heat map for each time period—a rasterized image colored with the scale determined from the deciles described above.
(The smoothing process in this step also provides an additional layer of anonymity. For example, in the case of a single high-rate lattice point surrounded by zero-rate points, the smoothing would “blur” the distinctive rate by generating points of intermediary rates nearby. Where a map contains areas of high population density with relatively few events, this smoothing also ensures the visualization does not imply the few events are more likely to occur on one neighborhood block than another.)
- Because time intervals in public health data are typically quite long—data might be collected on a monthly, yearly, or every-five-years basis—the above process typically results in only a few static heat maps, which yields a choppy animation when strung together in sequence. To create a fluid animation, another interpolation technique generates n additional, intermediate frames by estimating rates at each lattice point (i.e., z values) based on the known z values at the known time intervals. The number of additional frames, n, is determined by balancing processing power limitations and the frame rate required to produce a sufficiently fluid animation experience.
Green River – White Paper – HIPAA Checker
Read Green River’s HIPAA Checker white paper—exploring tools, methods, and best practices for assessing privacy risk and ensuring compliance.
Green River – News – My Healthy Community Featured in Delaware Journal of Public Health
Green River was pleased to collaborate with state epidemiologist Tabatha N. Offutt-Powell and her colleagues at the Delaware Department of Health and Social Services (DHSS) on an article published in the July 2021 issue of the Delaware Journal of Public Health (DJPH)
